Run and serve your pipelines
Data scientists have a crucial role in the creation and implementation of machine learning models, converting advanced algorithms into useful applications. In tasks like data processing, training, scheduling, and model deployment, data scientists often face the challenge of initiating pipelines using different methods while efficiently handling various inputs. This adaptability is vital because it allows them to address a wide range of scenarios and demands.
To streamline this process, the MLOps platform provides a robust and user-friendly deployment features, empowering data scientists to execute and serve their pipelines efficiently.
Learn about the various ways to execute your pipelines, which include:
- Pipeline run
- Pipeline deployment, with 2 execution rules
- Endpoint rule
- Periodic rule
One of the fundamental elements provided by the MLOps platform to run and serve your models is the ability to customize the sources of the inputs you provide to a pipeline and the ways you want to retrieve your outputs. The main idea is to easily connect different data sources to your inputs (data directly coming from the final user, or coming from the environment for example) and destinations (delivering output to the final user, writing it in the data store ...). This is known as mapping in the platform, and it plays a central role when creating deployments or running pipelines.
Summary
Prerequisites
Before using the Craft AI platform, make sure you have completed the following prerequisites:
- Get access to an environment
- Connect the SDK
- Create a step
- Create a pipeline
Info
Make sure that your code inside your step with inputs/outputs is able to read inputs from function parameters and send outputs with the return of the function.
More information here.
How to execute your pipeline
As a data scientist, I want to be able to execute my Python code contained in my pipelines in various scenarios :
- I (or data scientist in my team) want to launch my pipeline on the fly via the craft AI SDK, so I can use the run pipeline.
- I want to be able to make my pipeline accessible to external users, inside or outside my organization, via a Application Programmatic Interface (API), I can use the endpoint deployment feature to accomplish this.
- I want my pipeline to be automatically execute at regular intervals without manual intervention, the periodic deployment feature can be employed.
Run your pipeline
The run pipeline functionality enables you to trigger a pipeline directly from the Craft AI platform's SDK. This option offers the advantage of being user-friendly and efficient.
Please note that the run pipeline feature is exclusively accessible through the Craft AI SDK and requires proper connection to the appropriate platform environment. It is recommended for conducting experiments and conducting internal testing purposes.
To execute a run on a pipeline with no input and no output, simply use this function:
To execute a run on a pipeline with inputs and outputs, you can use the same function and add the parameter inputs and give an object with inputs' names as keys (should be the same name as defined in input object give at the step creation) and values you want to provide to your step at execution:
# Creating an object with predefined input values for the run,
# which will be provided as inputs to the run pipeline function
inputs_values = {
"number1": 9, # Value for Input "number1" of the step (defined during step creation)
"number2": 6 # Value for Input "number2" of the step (defined during step creation)
}
# Running the Pipeline and Receiving Output
output_values = sdk.run_pipeline(pipeline_name="your-pipeline-name", inputs=inputs_values)
print (outputs_values["outputs"])
For example, you can obtain an output like this :
>> {
'output_name_1': 'Lorem ipsum dolor sit amet, consectetur adipiscing elit.',
'output_name_2': 42
}
This function will return you the output of your pipeline. Like the inputs, it’s represented as an object with the outputs' name as keys and the outputs values as values.
Warning
Don’t forget to adapt your code to get value from input and return output. You must have created inputs and outputs objects at the step creation stage to get values. More information here.
It is also possible to run a pipeline with specific mapping (to connect inputs/outputs to the data store, environment variable, etc.), that will be covered in this section.
Create an endpoint
Triggering a pipeline via an endpoint will enable you to make your application available from any programming language/tool (website, mobile application, etc.).
To make your pipeline available via an endpoint, we need to create a deployment using the create_deployment() function which has the execution_rule parameter set as endpoint. In return, we'll get the URL of the endpoint and its authentication token so that we can call it and trigger our pipeline.
# Deployment creation with endpoint as execution rule
endpoint_info = sdk.create_deployment(
execution_rule="endpoint",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
)
Note
Here, we focus mainly on the platform's SDK interface.
However, it is possible to deploy a pipeline directly from the web interface by going to the Pipelines page, selecting a pipeline and then clicking the Deploy button.
You can trigger this endpoint from anywhere with any programming language if you have:
- Environment URL (Can be found in web UI and it’s the same you have used to initiate your SDK)
- Deployment name
- Endpoint token (given as result of the deployment creation, which secures access to the endpoint)
To trigger the deployed pipeline as an endpoint, you have a couple of options:
-
Utilize the dedicated function provided by the Craft AI SDK.
-
Implement a HTTP request to the endpoint using any programming language, similar to the example shown with the command
curl: -
An other example with
Javascriptsyntax (usingaxios) :const axios = require('axios'); const ENDPOINT_TOKEN = '<ENDPOINT_TOKEN>'; const CRAFT_AI_ENVIRONMENT_URL = '<CRAFT_AI_ENVIRONMENT_URL>'; const DEPLOYMENT_NAME = '<DEPLOYMENT_NAME>'; const headers = { 'Authorization': `EndpointToken ${ENDPOINT_TOKEN}` }; const url = `${CRAFT_AI_ENVIRONMENT_URL}/endpoints/${DEPLOYMENT_NAME}`; axios.post(url, null, { headers }) .then(response => { console.log('Response:', response.data); }) .catch(error => { console.error('Error:', error.message); });
Info
The URL of your endpoint follows the structure : <CRAFT_AI_ENVIRONMENT_URL>/endpoints/<YOUR_DEPLOYMENT_NAME>
The inputs and outputs defined in your step are automatically linked to the deployment and consequently to the endpoint. You can therefore send a JSON within your request where the parameters correspond to the step inputs so that it can be used as a parameter for your function in the step. The deployment will return a similar object with your outputs as parameters.
You can call the endpoint with inputs using the SDK function or with any other programming language (like before) by specifying the inputs in JSON format in the request body.
-
With Craft AI SDK :
# Value of inputs to be given to trigger pipeline function inputs_values = { "number1": 9, # Input "number1" defined in step creation "number2": 6 # Input "number2" defined in step creation } # Execution of pipeline using the endpoint sdk.trigger_endpoint( endpoint_name="your-deployment-name", endpoint_token=endpoint_info["endpoint_token"] # Token recieve after deployment creation inputs=inputs_values ) -
With
curl: -
With
JavaScriptusingaxios:const axios = require('axios'); const ENDPOINT_TOKEN = '<ENDPOINT_TOKEN>'; const CRAFT_AI_ENVIRONMENT_URL = '<CRAFT_AI_ENVIRONMENT_URL>'; const YOUR_DEPLOYMENT_NAME = '<YOUR-DEPLOYMENT-NAME>'; const requestData = { number1: 9, number2: 6 }; const config = { headers: { 'Authorization': `EndpointToken ${ENDPOINT_TOKEN}`, 'Content-Type': 'application/json' } }; const url = `${CRAFT_AI_ENVIRONMENT_URL}/endpoints/${YOUR_DEPLOYMENT_NAME}`; axios.post(url, requestData, config) .then(response => { console.log('Response:', response.data); }) .catch(error => { console.error('Error:', error); });
Info
For inputs and outputs, don't forget to have adapted the step code, to have declared the inputs and outputs at step level and to have used types (string, integer, etc.) compatible with the data you are going to manipulate.
Periodic
You might need to trigger your Python code regularly, whether it's every X minutes, every hour, or at a specific date, automatically. To achieve this, you can create a periodic deployment for your pipeline. This type of deployment uses the CRON format for scheduling its triggers.
To set up a periodic deployment, you employ the same function as you would for endpoints. However, you specify the periodic trigger mode and define when it should trigger by providing a CRON rule in the schedule parameter.
deployment_info = sdk.create_deployment(
execution_rule="periodic",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
schedule="* * * * *" # Will be executed every minute of every day
)
More information and help about CRON here.
How to define sources and destinations for step inputs and outputs ?
In the previous section, we saw that deployments can be used to trigger the execution of a pipeline, but they can also be used to give and receive information via inputs and outputs. When a pipeline is triggered, it may need to receive or send this information to different sources or destinations.
Example:
In the diagram below, we assume that we have deployed an endpoint pipeline. An API is therefore available to the user who triggers the execution of the pipeline each time a request is sent to the API. The request can contain information required to execute the pipeline, just as the pipeline can send information back to the user, as shown in the diagram below.
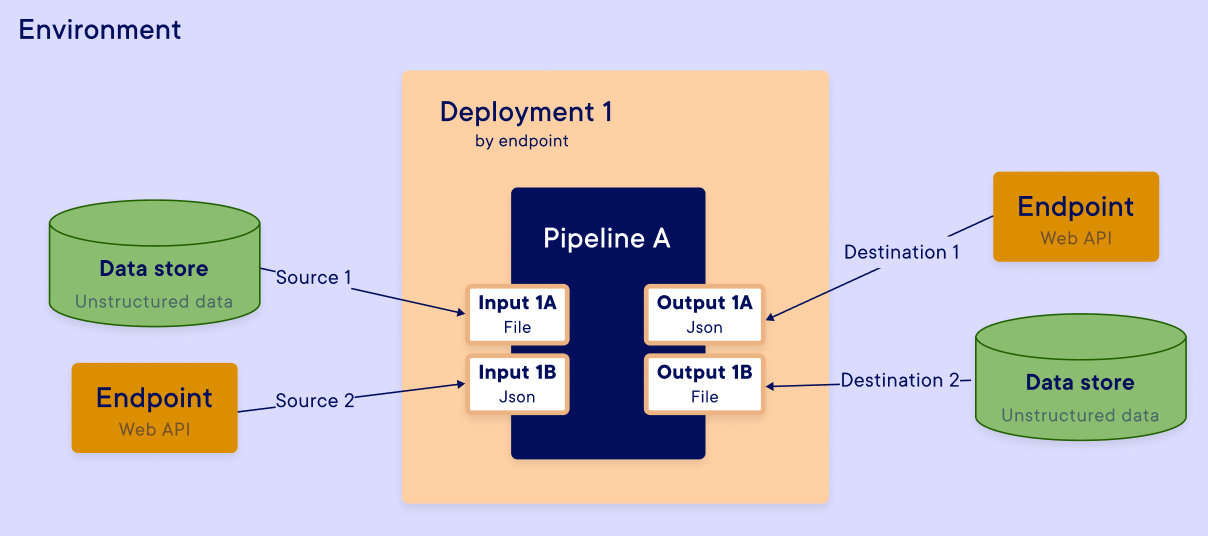
To direct these flows to the right place, the platform allows you to map the step inputs and outputs to different sources and destinations using InputSource and OutputDestination objects. We'll look at four different types of mapping:
- Constant mapping
- Endpoint mapping (value or file)
- Environment variable mapping
- None / void mapping
Inputs and outputs are not compatible with all types of deployment. To make things clearer, here is a summary table:
| Constant | Endpoint value | Endpoint file | Environment variable | Data store file | None / void | |
|---|---|---|---|---|---|---|
| Run | ✅ | ❌ | ❌ | ✅ (input only) | ✅ | ✅ |
| Endpoint | ✅ | ✅ | ✅ (limited to 1 file per call) | ✅ (input only) | ✅ | ✅ |
| Periodic | ✅ | ❌ | ❌ | ✅ (input only) | ✅ | ✅ |
Constant
If I want my deployment to always use the same value as input, I can use a mapping to a constant.
Info
Note that the same pipeline can have multiple deployments with multiple different constant values for the same input.
We will be using the constant value for an endpoint deployment here, but the process is the same for other types of deployment (periodic).
To do this, we create an InputSource object for each input in the pipeline that we want to deploy, specifying the name of the input for each mapping and the value of the input using the constant_value parameter.
Example :
# Endpoint Input mapping
endpoint_input1 = InputSource(
step_input_name="number1",
constant_value=6,
)
endpoint_input2 = InputSource(
step_input_name="number2",
constant_value=3,
)
# Deployment creation using inputSource object
endpoint_info = sdk.create_deployment(
execution_rule="endpoint",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
inputs_mapping=[endpoint_input1, endpoint_input2]
)
Warning
Step must be created with one or more inputs and the code contained in my step must be suitable for receiving a constant. More information about it here.
All input types are compatible, except for file.
Endpoint
As explained above, when a deployment is of the endpoint type, the inputs and outputs of the associated steps have as their default source and destination the parameters of the HTTP request.
You can therefore send a JSON within your request where the keys correspond to the step inputs so that it can be used as parameters for your function in the step. The deployment will return a similar object with your outputs as keys.
If you need to change this default behavior, you can do so using InputSource and OutputDestination. You can define new names that will only be seen at the endpoint level for the external user. It allows you to specify under which names should inputs be passed in the request JSON by your final user or for the outputs, under which names they will be returned.
This input mapping works with any type of input or output (integer, file, string, etc.).
# Endpoint Input mapping
endpoint_input1 = InputSource(
step_input_name="number1",
endpoint_input_name="number_a",
)
endpoint_input2 = InputSource(
step_input_name="number2",
endpoint_input_name="number_b",
)
endpoint_output = OutputDestination(
step_output_name="number3",
endpoint_output_name="result",
)
# Deployment creation using 2 input mapping and 1 ouptut mapping
endpoint_info = sdk.create_deployment(
execution_rule="endpoint",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
inputs_mapping=[endpoint_input1, endpoint_input2],
outputs_mapping=[endpoint_output]
)
Now that we have created our deployment, we can trigger the pipeline through the endpoint by passing the inputs and reading the outputs with the new mappings.
# Value of inputs to be given to trigger pipeline function
inputs_values = {
"number_a": 9, # Using mapping defined before linked to number1
"number_b": 6 # Using mapping defined before linked to number2
}
# Execution of pipeline using the endpoint
endpointOutput = sdk.trigger_endpoint(
endpoint_name="your-deployment-name",
endpoint_token=endpoint_info["endpoint_token"] # Token received after deployment creation
inputs=inputs_values
)
# Print result, note you should go into "outputs" before
print (endpointOutput["outputs"]["result"])
These changes are effective for any endpoint trigger method (curl, JS, etc.).
Info
Obviously, this type of mapping is only available if the deployment is an endpoint.
Environment variable
As a data scientist, I may need to use data common for my entire environment in my pipeline. This can be achieved by mapping environment variables to inputs.
To do this, we also use the mapping system with the InputSource object. Environment variables are only available for inputs and not for outputs (but it is still possible to define them directly in the step code).
First, let's look at how to initialize the two environment variables (on the platform environment), we're going to use:
# Creation of env variable for input1
sdk.create_or_update_environment_variable(
environment_variable_name="RECETTE_VAR_ENV_INPUT1",
environment_variable_value=6
)
# Creation of env variable for input2
sdk.create_or_update_environment_variable(
environment_variable_name="RECETTE_VAR_ENV_INPUT2",
environment_variable_value=4
)
Now, we can create an InputSource object and use it at the deployment creation.
# Creation of InputSource to get env variable into input
endpoint_input1 = InputSource(
step_input_name="number1",
environment_variable_name="RECETTE_VAR_ENV_INPUT1",
)
endpoint_input2 = InputSource(
step_input_name="number2",
environment_variable_name="RECETTE_VAR_ENV_INPUT2",
)
# Endpoint creation
endpoint_info = sdk.create_deployment(
execution_rule="endpoint",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
inputs_mapping=[endpoint_input1, endpoint_input2]
)
The deployment is created, we can trigger it without giving any object into data of HTTP request, it will take current environment variable value.
# Value of inputs to be given to execute pipeline function
inputs_value = {
"number_a": 9, # Using mapping defined before linked to number1
"number_b": 6 # Using mapping defined before linked to number2
}
# Execution of pipeline using the endpoint
sdk.trigger_endpoint(
endpoint_name="your-deployment-name",
endpoint_token=endpoint_info["endpoint_token"] # Token recieve after deployment creation
inputs=inputs_value
)
Data store
You may need to transfer files between your data store and your step (in one direction or the other). To do this, you can also use inputs and outputs mapping system. You'll find all the explanations you need on this page.
Void / None
All step inputs and outputs have to be mapped when you deploy a pipeline with inputs and outputs (otherwise it will raise an error when creating the deployment). If you don't really want to give/receive data in these inputs and outputs, you can map them to None. This will create a None object in Python for the inputs and send the outputs into the void.
# Endpoint Input mapping
endpoint_input1 = InputSource(
step_input_name="number1",
is_null=True,
)
endpoint_input2 = InputSource(
step_input_name="number2",
is_null=True,
)
endpoint_output = OutputDestination(
step_output_name="number3",
is_null=True
)
# Deployment creation using 2 input mappings and 1 ouptut mapping
endpoint_info = sdk.create_deployment(
execution_rule="endpoint",
pipeline_name="your-pipeline-name",
deployment_name="your-deployment-name",
inputs_mapping=[endpoint_input1, endpoint_input2],
outputs_mapping=[endpoint_output]
)
Now that the deployment has been created, it can be triggered without giving or receiving any input or output.