Define the pipeline sources and destinations
A deployment is a way to run a Machine Learning pipeline in a repeatable and automated way. First, you have to choose one of the 2 deployments methods.
Then, you need to connect the pipeline inputs and outputs with the desired sources and destinations.
Sources : This is the origin of the data that you want to connect to the pipeline inputs. The data can come from the data store, from environment variables, from constants or from the endpoint (if this deployment method has been chosen).
Destinations : This is the data drop point that you want to connect to the pipeline outputs. The data can go to the data store or to the endpoint (if this deployment method has been chosen).
Note
On this page, we will mainly focus on the platform's SDK interface.
However, it is possible to deploy a pipeline directly from the web interface by going to the Pipelines page, selecting a pipeline and then clicking the Deploy button.
Summary
| Objects name | Constructor | Return type | Description |
|---|---|---|---|
| InputSource | InputSource(step_input_name, required=False, default=None) | InputSource Object | Create a mapping source object for deployment. |
| OutputDestination | OutputDestination(step_output_name, endpoint_output_name, required=False, default=None) | OutputDestination Object | Create a mapping destination object for deployment. |
General function of the I/O mapping
Mapping rules
When you start a new deployment, the data flow is configured with a mapping. You can create this mapping in two ways: auto mapping (only available with endpoint trigger) or manual mapping in the SDK or UI.
Auto mapping automatically maps all inputs to endpoint variables for sources. If you need a different mapping or another trigger, you must map your inputs and outputs manually.
Auto mapping Example
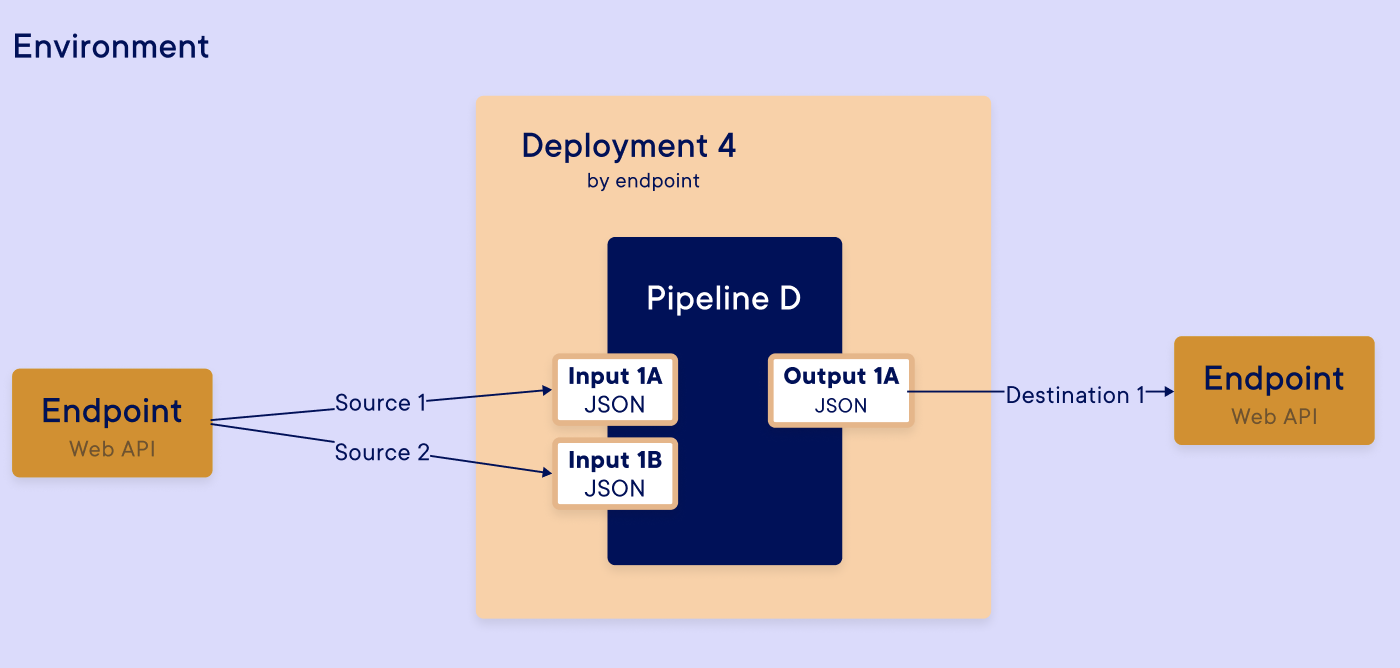
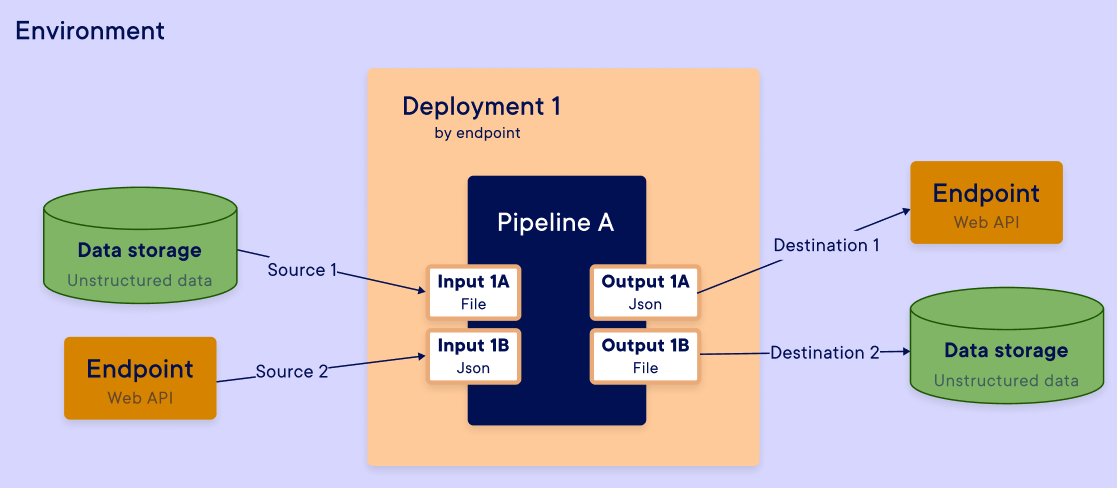
For each input / output, you had defined a data type in step. This data type will be the same as the mapped step input / output. You need to map the good source and destination with the good data type :
- Endpoint (input and output) → Variable (string, number, ...) and file
- Data store → Only file
- Constant → Only variable (string, number, ...)
- Environment variable → Only variable (string, number, ...)
- None → Variable (string, number, ...) and file
Limitations
The inputs (as outputs) of a step mapped through the endpoint (default mapping) can consist of only a single file or multiple variables. Thus, if you use deployment by triggering an endpoint, you cannot have multiple files as inputs or outputs due to a technical limitation of the API calls.
To have multiple files as the inputs or outputs of an endpoint, you can compress the files into a single file (for example, with the [tar]{.title-ref} command) to be sent in the API call.
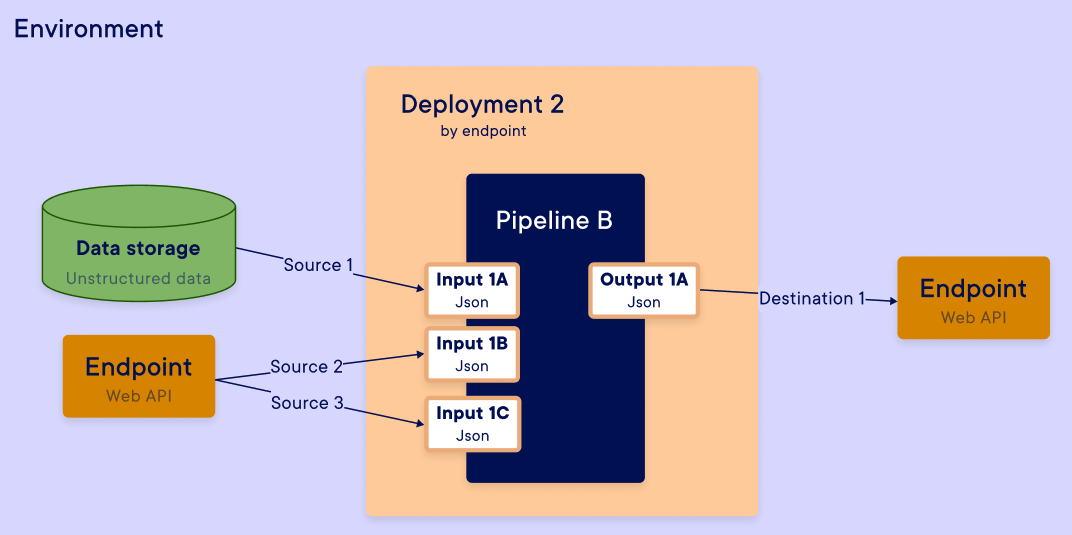
Examples: You can do
Warning
The data store is not yet available for the input/output mapping, but it's coming soon, so stay tuned.
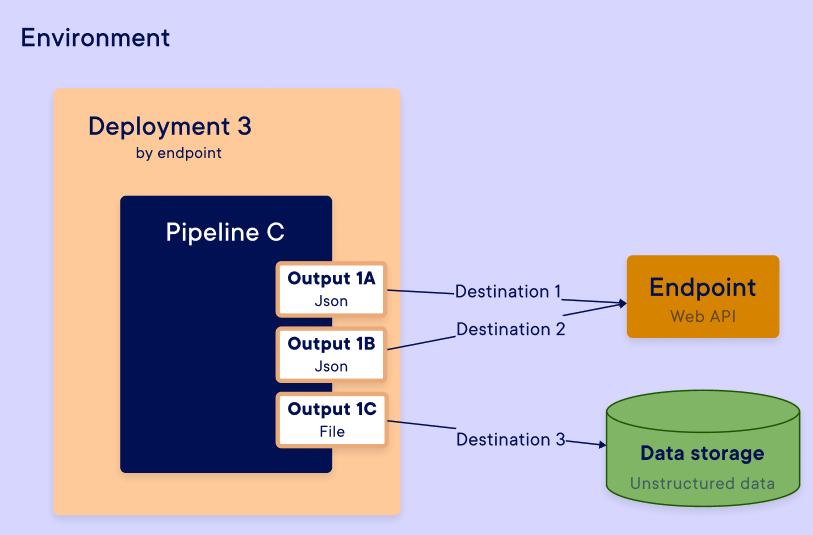
Examples: You can't do
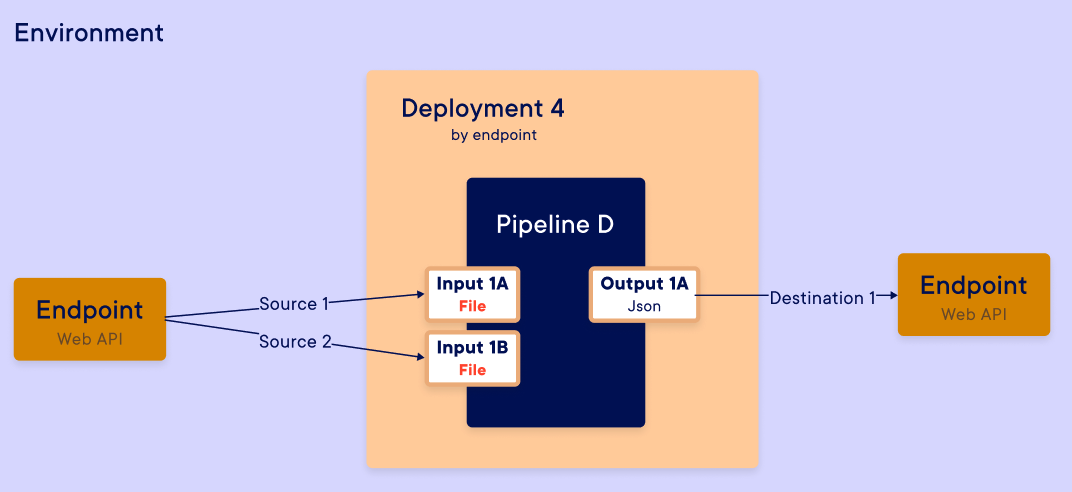
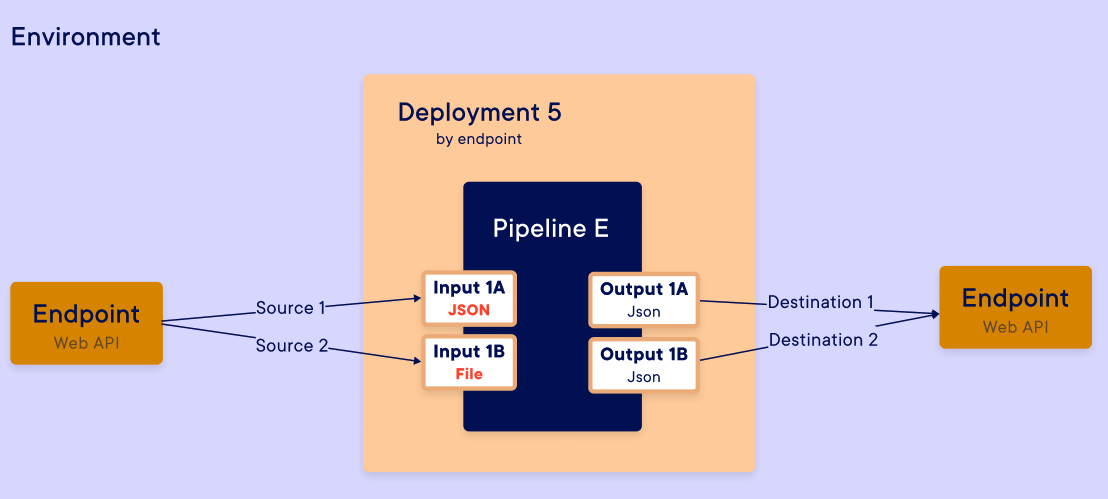
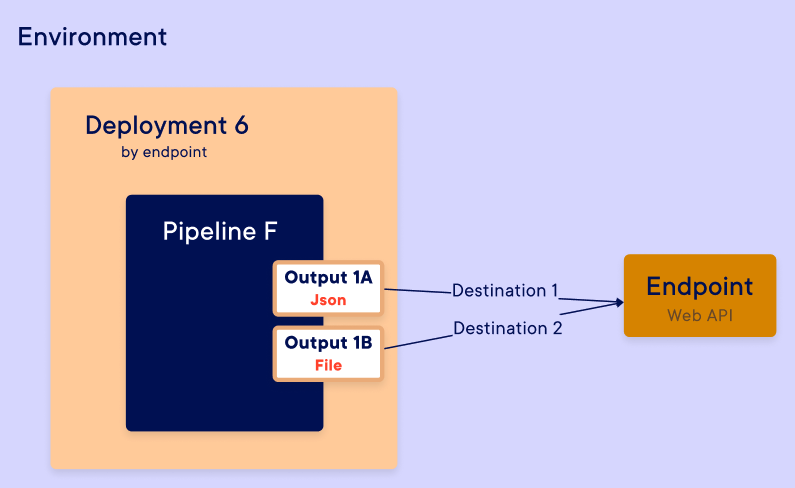
Creation input mapping
Import Dependencies
Before creating a mapping between the input/output of a pipeline and the sources/destinations of an endpoint, you need to import the InputSource and OutputDestination objects from the SDK.
Function Definition
For each input of your pipeline, in manual mapping, you need to create a
mapping object that will be given to the create_deployment() function.
boat_endpoint_input = InputSource(
step_input_name="apply_model",
## Choose from one of these parameters
endpoint_input_name="boat", ## For mapping with an endpoint
environment_variable_name=None, ## For mapping with an environment variable
constant_value=None, ## For mapping with a constant value
is_null=True ## For mapping with None
is_required=True,
default_value="empty",
)
Parameters
step_input_name(str): name of the input at the step level to which the deployment input will be linked to
Different possible sources:
endpoint_input_name(str, optional): name of the input at the endpoint level to which the step input will be linked toenvironment_variable_name(str, optional): name of the environment variable to which the step input will be linked toconstant_value(Any, optional): a constant value to which the step input will be linked to
Other parameters:
is_null(True, optional): if specified, the input will not take any value at execution timedefault_value(Any, optional): this parameter can only be specified if the deployment is an endpoint. In this case, if nothing is passed at the endpoint level, the step input will take the default_valueis_required(bool, optional): this parameter can only be specified if the deployment is an endpoint.If set to True, the corresponding endpoint input should be provided at execution time.
Return
An InputSource object that can be used in the deployment creation in the dictionary format.
Additional parameters for source definition
By default, the source is configured as an endpoint parameter, but you can configure a different source for your mapping. For each source, you have to add 1 parameter to :
- Define the type of source with the name of parameter added
- Precise element about the source
We will list all parameters you can have in your input mapping.
Warning
You can only add 1 parameter of source definition. By default, it's always endpoint source that is configured.
-
Endpoint source
Parameter name : endpoint_input_name
Source from : Outside through the endpoint
Value to put in parameter : name of the input received by the endpoint in the body of the HTTP call
Example :
-
Data store source
Parameter name : datastore_path
Source from : file content from the data store
Value to put in parameter : path to a data store file
Example :
data_store_input = InputSource( step_input_name="trainingData", datastore_path="path/to/trainingData.csv", )Example step code to read file :
-
Constant source
Parameter name : constant_value
Source from : static value
Value to put in parameter : direct value
Example :
-
Environment variable
Parameter name : environment_variable_name
Source from : the variables set at the level of an Environment in the platform
Value to put in parameter : name of the environment variable
Example :
-
None value
Parameter name : no_value
Destination to : void
Value to put in parameter :
TrueExample :
Create output mapping
Import dependency
Before creating mapping between input / output of pipeline and sources / destination of endpoint, you have to import InputSource and OutputDestination objects from SDK.
Function definition
For each output of your pipeline, in manual mapping, you have to create an object, that will be given to create_deployment() function.
endpoint_output = OutputDestination(
step_output_name="pred_0",
## Choose from one of these parameters
endpoint_output_name="pred_0", ## For mapping with an endpoint
is_null=True ## For mapping with None
)
Parameters
step_output_name(str) - the specific output in the stependpoint_output_name(str, optional) -- Name of the endpoint output to which the output is mapped.is_null(True, optional) -- If specified, the output is not exposed as a deployment output.
Return
An OutputSource object who can be used in the deployment creation.
Additional parameter for destination definition
By default, the destination is configured as an endpoint parameter, but can configure a different source for your mapping. For each source, you have to add 1 parameter to :
- Define the type of destination with the name of parameter added
- Precise element about the destination
We will list all parameters you can have in your output mapping.
Warning
You have to add just 1 parameter of destination definition. If a parameter destination is missing, the function will generate an error (as opposed to input mapping).
-
Endpoint destination
Parameter name : endpoint_output_name
Destination to : Outside through the endpoint
Value to put in parameter : name of the output received by the endpoint in the body of the HTTP call
Example :
-
Data store destination
Parameter name : datastore_path
Destination to : write a file into the data store
Value to put in parameter : path to a data store folder
Example :
prediction_deployment_ouput = OutputDestination( step_output_name="history_prediction", datastore_path="path/to/history/folder.csv", )Example step code to send file :
def stepFileIO () : text_file = open('history_prediction.txt', 'wb') # Open the file in binary mode text_file.write("Result of step send in file output :) ".encode('utf-8')) # Encode the string to bytes text_file.close() fileOjb = {"history_prediction" : {"path": "history_prediction.txt"}} return fileOjbDynamic path :
You can also specify a dynamic path for the file to be uploaded by using one of the following patterns in your datastore path:
- {execution_id}: The execution id of the deployment.
- {date}: The date of the execution in truncated ISO 8601 (YYYYMMDD) format.
- {date_time}: The date of the execution in ISO 8601 (YYYYM-MDD_hhmmss) format.
Example with a dynamic path :
-
Void destination
Parameter name : no_destination
Destination to : void
Value to put in parameter :
TrueExample :
4. Generate new endpoint token
If you need to alter the endpoint token for an endpoint, you can generate a new one with the following SDK function.
Warning
This will permanently deactivate the previous token.