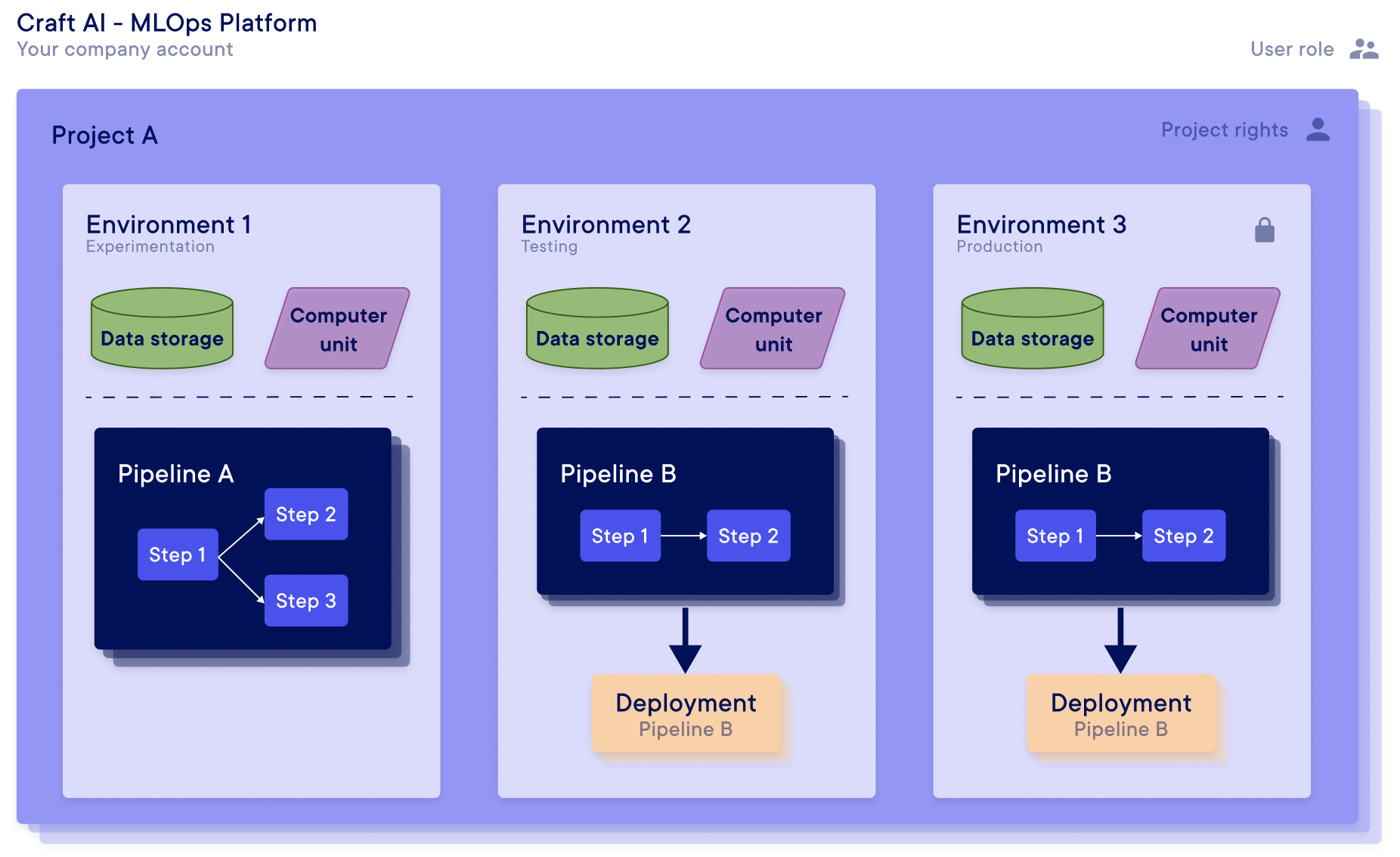
Environments
An environment is the infrastructure used by the Platform to store data and run computation.
The main objectives of the environments are:
- Building and managing infrastructures in a few clicks without DevOps skills.
- Ensuring an efficient and automated use of computing resources.
- Enabling large scale deployment of your code without the need of rewriting it for production.
- Fine-tuning the size of your environments according to the needs of your projects.
- Easily building dedicated environments for each phase of the project to adopt software development best practices.
Our environments can be created on AWS or GCP but also on S3NS or Scaleway if you prefer a European based provider.
Each environment is independant from the others, isolated in computing and storage and nothing is shared across different environments.
An environment is composed of:
- a cluster: cloud computing resources based on a fully managed Kubernetes service. The pipelines created in an environment are executed on the associated cluster.
- a Data store: cloud storage to save and retrieve any amount of data at any time. The results of the pipelines and metrics generated by the Platform are also stored on the Data store.
It is possible to tag environments with 3 types:
- Experimentation : To test your models on the Platform.
- Testing : To finalise your developments before shipping in production.
- Production : To use your pipelines in production and secure the access.
For the moment, these tags are just displayed to help you check what kind of environment you created. In a later version, we will introduce a migration workflow that allows you to develop features, test them in a controlled place, and then ship to production environment without any manual pipeline re-creation steps.
If you declare an environment as Production, it may have a more restricted access rights and may need some user management (you can set rights that exclude access to all productions environments).